 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
如果你要存储整个学校的学生的成绩信息(姓名,年级,系别,成绩,性别),你不准备准备选择哪种数据存储结构呢?()
A.SQL
B.Key-ValuenoSQL
C.Excel
D.Hive(HadoopSQL类似)
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.SQL
B.Key-ValuenoSQL
C.Excel
D.Hive(HadoopSQL类似)
如果结果不匹配,请 联系老师 获取答案
 更多“如果你要存储整个学校的学生的成绩信息(姓名,年级,系别,成绩…”相关的问题
更多“如果你要存储整个学校的学生的成绩信息(姓名,年级,系别,成绩…”相关的问题
现有关系数据库如下:
学生(学号,姓名,性别,专业、奖学金)
课程(课程号,课程名,学分)
选课(学号,课程号,分数)
用SQL语言实现下列(1)—(5)小题:
(1)列出学号为“98001”的已有成绩的各门课名称与成绩
(2)删除姓名为“陈红”的所有选课记录
(3)检索获得奖学金、并且至少有一门课程成绩在90分以上的学生信息,包括学号、姓名和专业;
(4)将对选课表的全部权限授予用户王平,并且王平可以授权给其它用户;
(5)求学号为“785222”的学生所选课程的总学分
刚从法学院毕业的学生的起薪中位数由下式决定:
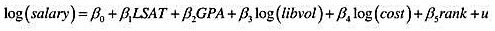
其中,LSAT’是整个待毕业年级LSAT成绩的中位数,GPA是该年级大学GPA的中位数,libvol是法学院图书馆的藏书量,cost是进入法学院每年的费用,而rank是法学院的排名(rank=1的法学院是最好的)。
(i)解释为什么我们预期βs ≤0。
(ii)你预计其他斜率参数的符号如何?给出你的理由。
(iii)使用LAWSCH85.RAW中的数据,估计出来的方程是
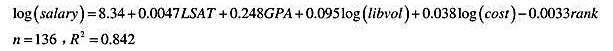
在其他条件不变的情况下,预计GPA中位数相差1分会导致薪水有多大差别?(用百分比报告你的答案。)
(iv)解释变量log(ibvol)的系数。
(v)你是否认为,应该进入一个排名更高的法学院?从预计的起薪来看,排名相差20位的价值有多大?
假设你想如同例6.3那样估计出勤率对学生成绩的影响。一个基本模型是:
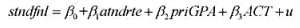
其中变量定义与第6章相同。
(i) 令dist为学生住宿区到教学大楼的距离。你认为dist与u不相关吗?
(ii) 假定dist与u不相关, 要成为a in dr le的一个有效IV, dist还必须另外满足什么假定?
(iii) 假定我们如在方程(6.18) 中一样增添交互项pri GPA-at nd rte:
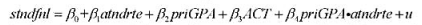
若ct nd rte与u相关, 则一般认为pri GPA也与u相关。priG PAra tnd rte的一个好I将是什么呢?[提示:若E(ul pri GPA, ACT, dst) =0(在pri GPA、ACT、dst均外生时出现) , 则pri GPA和dit的任何函数都与u不相关。]
编程序,逐个输入某科课程若干学生成绩(百分制),分别统计其中的优等生有多少个?(优等生的成绩大于85)不及格学生有多少个?(不及格的成绩小于60)如果输入的数为0,则停止输入结束程序。
利用GPA2.RAW中有关4137名大学生的数据,用OLS估计了如下方程:
colgpa=1.392-0.0135hsperc+0.00148sat
n=4137,R2=0.273
其中,colgpa以四分制度量,hsperc是在高中班上名次的百分位数(比方说,hsperc=5,就意味着位于班上前5%之列),而sat是在学生能力测验中数学和语言的综合成绩。
(i)为什么hsperc的系数为负也讲得通?
(ii)当hsperc=20和sat=1050时,大学GPA的预测值是多少?
(iii)假设两个在高中班上具有同样百分位数的高中毕业生A和B,但A学生的SAT分数要高出140分(在样本中相当于一倍的标准差),那么,预计这两个学生的大学GPA相差多少?这个差距大吗?
(iv)保持hsperc不变,SAT的分数相差多少,才能导致预测的colgpa相差0.50或四分制的半分?评论你的结论。
现有关系数据库如下: 学生(学号,姓名,性别,专业、奖学金) 课程(课程号,名称,学分) 学习(学号,课程号,分数) 用 SQL 语言实现下列 1—3 小题:
(1)检索没有获得奖学金、同时至少有一门课程成绩在 95 分以上的学生信息,包括学号、姓名和专业
(2)检索没有任何一门课程成绩在 80 分以下的所有学生的信息,包括学号、姓名和专业
(3)定义学生成绩得过满分(100 分)的课程视图 AAA,包括课程号、名称和学分
A.>69or<80
B.Between70and80
C.>=70and<80
D.in(70,79)

















